Social VR
Motivation
This project started by thinking about the value of sharing an experience. One can capture a proof of a spatial existence or a temporal state or a way to express their social identities. One may ask then how will this be transferable to the virtual world where VR users can live similar shareable experiences from game achievements to purely visually fascinating scenes? To answer this question, I decided to focus on a particular phenomenon that thrived on social media: selfies. Selfie as a concept may look new as it's intrinsic to the emergence of social media, but I can date back its origin to self-portraits but also to standard portraits. Self-portraits were based on this particular idea of taking control of the take which makes the picture an active action and a decision to create a content to be shared. In portraits, I find a more elaborate "mise-enscene" which is an important aspect that we find also in selfies.The selfie phenomenon is based on these two rules : an active take in a special scene. I wanted our project to be a way to transfer this mechanism to the virtual world. By the immersive properties of VR, I can say that the user is actually transported in space-and-probably time and is living new experiences that are comparable to travelling and sightseeing and are at their core sharable to everyone (VR-accustomed or not). This project was created with another two developer in context of creating something new in VR in order to contribute to a paper.
Describing the player and the scene
First of all, I am not using the regular OVRCameraRig but OVRPlayerController, this gives us the ability to move more freely in the scene, since the controller joystick can be used. The player contains a head and also two controllers are shown. The left one is the controller that he/she can interact with and the right one contains the two displays, one for the in-game feed and the web camera feed.

When the user takes a photo we need to find a way to display it. I use cannons to throw the photos in front of the player. These cannons follow the player, always face his direction and they are placed in a circular diameter.When a photo is taken, then they fire their photos to appear in front of him/her. The main theme in our scene is giants and they are scattered throughout the area. Our application contains three main scenes that the user can interact with, I will explain them going from the simplest one to the most complex one. The first scene is called the Lava Giant. There is a lava area that contains a Lava giant, although he may seem dangerous he is only carefully watching the user as he/she passes by. There is no interaction with this scene, just the giant is moving his body the way in the direction that the user walks. In the second scene, magic happens, literally. The second area of our game is the complete opposite of a lava area, it is a snowy area. In this area, there is a skull that has flaming eyes. When the user touches the skull with the left controller then a series of particle effects start to appear. After they finish a second skull giant appears and he is constantly casting a magic spell.
The last scene is staged in an oasis. When the user sees the oasis he/she can make out two things: A sword with energy that is drawn in it and two giants facing each other. One of them is an earth golem or the protector of the oasis and the other one is a demon.

We have to mention that all the models are humanoid rigged models and they carry an animator component. The main idea of the project is to merge two given selfies.
Merging Feature
One taken in the game and one taken in real life. As for the result I chose to do this merging feature for both sides. Meaning I will have at the end two types of results. First one: The real background with the player's avatar and the second one: The background of the game with the actual physical body of the player.
Method Used
I looked for ways to extract the user in real life and the player in the game. Finally, I managed to narrow it down to 2 methods. The first one consisted of using deep learning techniques. It's mainly the use of convolutional networks in order to extract the silhouette of the user in real life. The second method was to use the built-in function "GrabCut" of OpenCVSharp plus asset of unity. After discussing the two methods I decided to go with the "GrabCut". I opted for this method, even with the knowledge that the deep learning technique will perform better, because the period dedicated to this project will not allow me to completely assimilate this method and understand how to use it in Unity. Also, it will take much longer to have a full working model ( gathering data set, building the model and training it). Now I am going to detail the full pipeline of my work and possible enhancements. I will also explain some key notions along the breakdown of the algorithm.
Calibration of the camera
Since the final images depend on real life images and on virtual elements, I need to have the two pictures taken in each world perfectly aligned, ie, each virtual element matches in size and position to its corresponding real element. This could be done by setting the virtual camera's intrinsic and extrinsic parameters equal to those of the webcam. For that, I mounted a webcam on one controller via a 3d printed piece and created a Virtual Camera ingame at the same position as the webcam by calculating manually the offset in angles and in position. I proceeded then to a camera calibration by inputting FOV values from the webcam specs. This process can be perfected by using chessboard calibration and making it in a future version a dynamic calibration.

Extracting the elements of interest
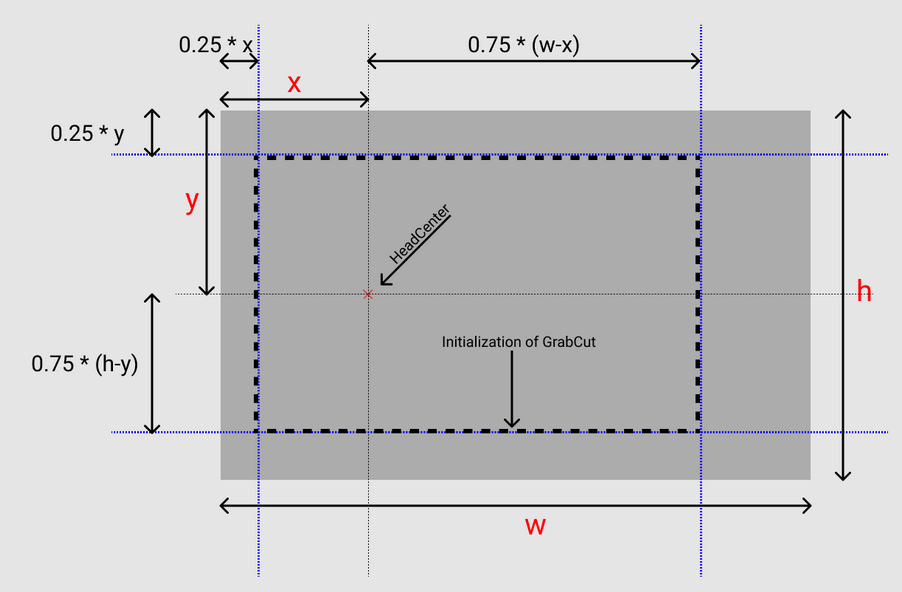
In this part, I am going to explain how I did extract the user in real life and in game. For that I used the built-in function Grabcut. Before heading to details, let's define the grabcut.Grabcut: GrabCut is an image segmentation method based on graph cuts. Starting with a user-specified bounding box around the object to be segmented, the algorithm estimates the color distribution of the target object and that of the background using a Gaussian mixture model. The built-in function that I use will give the mask that will define the object in interest(binary image). Based on this definition, I have now to define an initial rectangle. Assuming that both cameras, the virtual and the physical one are perfectly aligned, we used a method of the Camera�s class called WorldToScreenPoint. Using it on the virtual camera, I can pinpoint the position of any object on the screen.So we applied it to the head in the game and with the alignment's assumption I can say that it will also coincide with the head in real life. Right now I have the position of the head in pixels. Below, I showcase how I did define the initial rectangle in a simple figure:
Merging of the two seflies
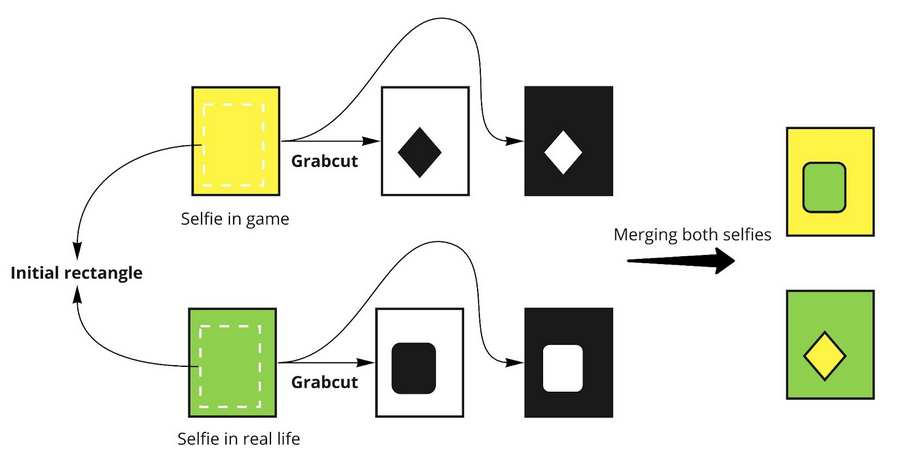
Using this rectangle I apply grabcut on both selfies. That will give me two masks corresponding to the two silhouettes. Using these masks, I can cut the interesting part in one picture and paste it on top of the other in the same position (The alignment assumption is still valid). The figure below highlights this process:
Optimization of the GrabCut method
After trying out this method, I noticed that the resulting masks are not as precise as I wanted. So I came up with a way to enhance our results especially for the in game selfie. As I know, GrabCut uses color distribution in order to distinguish between the background and the foreground. In order to use this technique at its fullest, I created a plane, having a uniform color, that will follow the player in the game from behind. Using layers in Unity, I made sure that this plane will be rendered only for the selfie virtual camera so it will not affect the game's experience. For the selfie in real life, I tried to use a green screen but the results were not as promising as expected. I assumed that the initialization of the rectangle or the lighting of the room are at fault. Using this rectangle we apply grabcut on both selfies. That will give me two masks corresponding to the two silhouettes. Using these masks, I can cut the interesting part in one picture and paste it on top of the other in the same position (The alignment assumption is still valid). The figure below highlights this process:

Results of this method
As you can see the result is not that realistic. In order to make them more plausible, I thought about removing the already existing element before pasting the new one using the inpainting method. This last method is also a built-in method in the OpenCVSharp asset. "Inpainting is a conservation process where damaged, deteriorating, or missing parts of an artwork are filled in to present a complete image". The built-in function for inpainting requires an initial mask of the object to remove. So we could use the masks defined by the grabCut algorithm.
Conclusion
I have described SelfieVR, a unity project where users can explore different scenes and share their ingame experience with mixed selfies with elements from both the virtual and the real worlds. The final prototype is an independent oculus app but the ideal version should be a Unity SDK that VR developers can import to their project to make every VR experience shareable in the form of fun selfies. SelfieVR can be used to capture a particular moment in the virtual world, an emotion or a scene. These selfies can then be shared on social media to engage other VR users but also non VR users. This aims ultimately at making the VR experience transcend its exotic nature and having everyone become accustomed to it in a way similar to real life experiences such as travelling and meeting other people.